
How Andromeda, GEM, Lattice, and the Adaptive Ranking Model changed ad delivery, and what your campaign architecture should look like now.
Meta didn't tweak its ad delivery system. It replaced it.
Over the past year, Meta rolled out four interconnected AI systems that fundamentally changed how ads are retrieved, ranked, and served. Most advertisers noticed the symptoms: campaigns that used to work stopped working, creative fatigue accelerated, costs spiked without explanation. But few understood the cause. And fewer still restructured their campaigns around it.
This post is the architecture I rebuilt from scratch in response to those changes. It's what I'm running now across every account I manage, and it makes up 80%+ of spend in my best-performing accounts. This is specifically for top-of-funnel prospecting: net new reach and scale. Retargeting and retention live in separate structures not covered here.
Before I walk through the campaign structure, you need to understand what changed underneath it. Because the structure only makes sense when you see what it's designed to feed.
The AI Stack: What Actually Changed
Meta's ad delivery now runs on four systems working in a hierarchy. Understanding how they interact is the difference between building campaigns that feed the machine and campaigns that fight it.
Andromeda: The Retrieval Engine
Andromeda is the first gate. Before any auction happens, before your bid or budget matter, Andromeda scans tens of millions of active ads and narrows them to roughly 1,000 candidates eligible to compete for an impression. If your ad doesn't make it through retrieval, nothing else matters.
Andromeda completed its global rollout in October 2025. It replaced the old rule-based retrieval system with deep neural networks powered by computer vision and semantic analysis. Instead of asking "does this user match the advertiser's targeting settings?" the system now asks "does this creative match this individual user's interests and behavior?"
Two things matter here. First, Andromeda clusters visually similar ads under the same Entity ID. Ten ads with the same product photo and different headlines? That's one ad in Andromeda's eyes. One retrieval ticket for all ten. This is why visual diversity isn't a nice-to-have — it's structural.
Second, Andromeda effectively makes your targeting settings a soft suggestion. The system will expand beyond your audience definitions if the creative signals suggest a better match elsewhere. Broad targeting isn't lazy. It's what the system is designed for.
GEM: The Foundation Model
GEM (Generative Ads Recommendation Model) is Meta's largest ads AI, trained at LLM scale across thousands of GPUs. Meta published the engineering paper in November 2025. GEM sits at the top of the hierarchy and teaches every other model in the stack through knowledge distillation.
GEM learns from both ads and organic content across every Meta surface. It doesn't just predict who will click. It predicts the entire sequence of actions a person takes before and after seeing an ad. It understands that someone who watched three Reels about coffee, then read a comment about espresso machines, then scrolled past a generic brand ad, is at a specific point in a purchase journey. GEM scores your ad based on whether it fits the next step in that sequence.
Since launching, GEM has driven a 5% increase in ad conversions on Instagram and 3% on Facebook Feed, with those gains doubling in Q3 2025 as Meta refined the architecture. GEM is now 4x more efficient at driving performance gains than Meta's original ranking models.
For advertisers, the implication is that creative diversity feeds GEM's ability to sequence ads. If you only provide one creative concept, GEM can only match you to one type of user at one point in their journey. More distinct creative gives GEM more ingredients to work with.
Lattice: The Ranking Architecture
Lattice is Meta's unified ad ranking system. It replaced hundreds of siloed models (each optimized for a single objective or surface) with one massive architecture that learns across all of them simultaneously. Reels performance informs Feed ranking. Click optimization informs conversion optimization. Everything teaches everything.
Lattice has increased ad quality by almost 12% and increased conversions by up to 6%. But the key innovation for advertisers is Sequence Learning. Lattice doesn't just evaluate single impressions. It looks at user behavior over weeks or months. It recognizes that a CEO might need to see your authority video four times before booking a call. Instead of punishing that ad because it didn't get a click today, Lattice recognizes its value in the sequence.
This is why 7-day learning periods matter. Lattice needs time to observe sequences, not just individual events.
Adaptive Ranking Model: LLM-Scale at Sub-Second Latency
Published in March 2026, Meta's Adaptive Ranking Model serves trillion-parameter models at sub-second latency. This is the infrastructure that makes everything else possible. It uses selective FP8 quantization, multi-card GPU sharding, and request-centric computation to run models that were previously too expensive to serve in real time.
The practical implication: Meta's ad system is now running models at a scale comparable to ChatGPT for every single ad impression, billions of times per day. The system is deeply intelligent, constantly retraining, and cross-connected. You can't hack it. Your only levers are creative diversity, signal quality, account simplicity, and patience during learning periods.
What This Means for Campaign Structure
Every one of these systems has structural implications for how you organize campaigns:
Andromeda means broad targeting and visual diversity are mandatory. Each visually distinct creative gets its own Entity ID and its own path through retrieval. More Entity IDs = more retrieval tickets = more chances to reach different user segments.
GEM means your creative should provide variety for sequencing. Different formats, different angles, different stages of awareness. GEM can't sequence what you don't give it.
Lattice means data density matters. Fragmenting your account into dozens of ad sets across dozens of campaigns starves every one of them. Lattice needs concentrated conversion data to learn sequences. 50 events per week per ad set is the minimum for the system to learn effectively.
Adaptive Ranking means 7-day learning periods are real, not a suggestion. The system needs time to observe user sequences and calibrate.
These aren't abstract principles. They dictate specific structural decisions about how many campaigns you run, how you organize ad sets, how you brief creative, and how you move winners through the system. What follows is the architecture that accounts for all of them.
The Architecture: Three Phases, One Flow
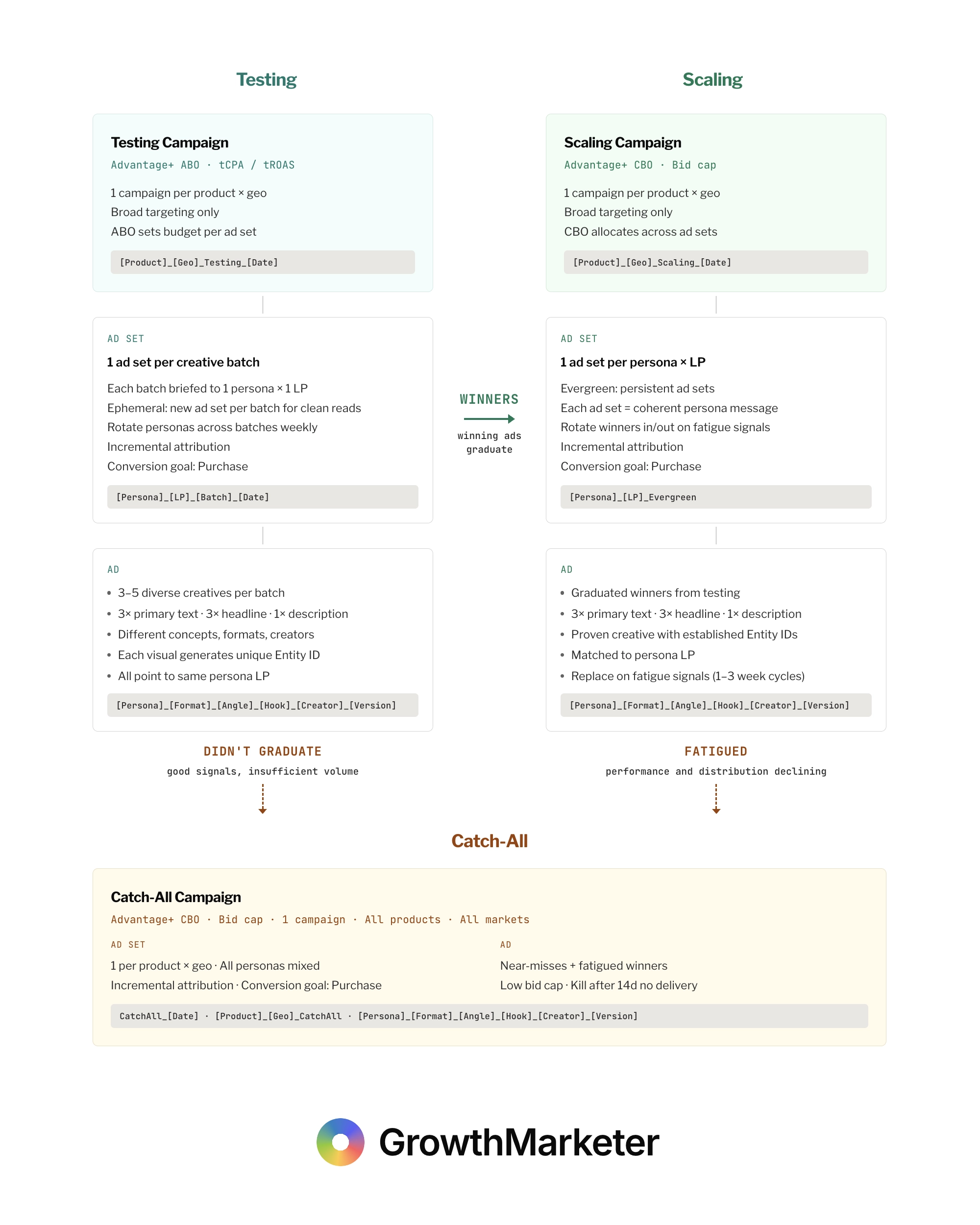
The structure has three campaign types: Testing, Scaling, and Catch-All. Each operates on different logic, different bid strategies, and different ad set lifecycles. Creative flows in one direction: left to right, top to bottom. Testing to Scaling. Near-misses and fatigued winners down to Catch-All. Nothing skips the line.
| Testing | Scaling | Catch-All | |
|---|---|---|---|
| Campaign | 1 per product × geo | 1 per product × geo | 1 campaign total |
| Type | Advantage+ ABO | Advantage+ CBO | Advantage+ CBO |
| Bid Strategy | tCPA / tROAS | Bid cap | Bid cap (0.7x) |
| Ad Sets | Ephemeral (per batch) | Evergreen (per persona) | Per product × geo |
| Conversion | Purchase | Purchase | Purchase |
| Attribution | Incremental | Incremental | Incremental |
Testing: The Left Side
Testing Campaign Setup
One campaign per product per country. I test primarily in the US, then expand winners to other geos in scaling. The campaign type is Advantage+ ABO, which gives me direct budget control on each ad set.
Testing Bid Strategy: tCPA / tROAS
I use tCPA or tROAS depending on the brand, product, and average order value. Target-based bidding gives the algorithm room to explore auctions for creative it's never delivered before. A hard bid cap on unproven ads kills delivery before you learn anything. tCPA/tROAS sets a soft guardrail: "try to stay near $40" without cutting off the learning. You might see a $60 conversion on day one and a $25 conversion on day three. That's the algorithm learning. Bid cap would have killed delivery after the $60.
I avoid Maximize Conversions and Maximize Conversion Value in testing. They give the algorithm no guardrail at all and can spend aggressively on unproven creative with no cost control.
Budget needs to be at least your target CPA multiplied by seven per ad set per day. Below that, the ad set never exits learning and you're burning money on inconclusive data.
Testing Ad Set Organization
Every ad set is a fresh batch of creative built around one persona and one landing page. Ad sets are ephemeral: one per batch, new ad set per batch for clean reads. No old creative dragging down new creative. No muddy data.
All ad sets optimize for purchase. All ad sets use incremental attribution so you're measuring actual lift, not modeled conversions. I rotate personas across batches weekly so each persona gets tested roughly every week and a half.
Creative Strategy and Entity IDs
Three to five ads per batch, each one visually distinct. This is the single most important detail in the entire structure. Andromeda clusters visually similar ads under one Entity ID. If your five ads look similar, Andromeda treats them as one ad with one retrieval ticket. Five genuinely different visuals means five Entity IDs, five retrieval tickets, five chances to be matched to different user segments.
"Different" means different concepts, different formats, different creators. Not different headline colors on the same product shot. Different images entirely. Different aspect ratios. Different people on screen.
Each ad gets three primary text options, three headlines, and one description. Meta handles the multivariate testing natively within each Entity ID. The visual diversity drives targeting through Andromeda. The text variations optimize conversion within each Entity ID.
Partnership Ads as an Entity ID Multiplier
Partnership ads (whitelisted creator content) have become a structural advantage under Andromeda, not just a creative tactic. The reason is Entity IDs. When a creator publishes an ad through their page, even if the angle, format, and product are identical to an ad on your brand page, Andromeda generates a completely new Entity ID. Same concept, different creator, different retrieval ticket.
This means partnership ads are an Entity ID multiplier. A winning angle that's exhausting its audience under your brand's Entity ID gets a fresh start through a creator's page. New retrieval ticket, new audience matching, new delivery trajectory.
Some of the best accounts I manage are running 30-40% of total spend through whitelisted creator content. That requires its own place in the campaign architecture. I treat creator batches the same way I treat brand batches in the testing framework: one ad set per creator per persona per landing page. Same graduation rules, same kill rules. The creator is just another variable in the naming convention, which is why the ad-level template includes a [Creator] field.
The accounts that are scaling most efficiently right now are the ones that figured out partnership ads aren't a bolt-on. They're a core part of the Entity ID strategy.
Graduation and Kill Rules
I run each batch for seven days. Seven days respects GEM and Lattice learning periods.
Graduation criteria (all three required):
| Metric | Threshold |
|---|---|
| CPA | Under 1.3x target |
| CTR | Above account median |
| Conversion events | 50+ in the testing window |
Kill rules:
| Signal | Action |
|---|---|
| CPA above 2x target | Cut after 5 consecutive days |
| No conversions | Cut after set spend based on target CPA |
| Trajectory | Watch days 3-5; cut early if clearly dead |
Scaling: The Right Side
Scaling Campaign Setup
Same structure: one campaign per product per country. But here I use Advantage+ CBO with a bid cap. CBO lets Meta allocate budget across ad sets based on performance. I'm no longer controlling budget per ad set because the creative is proven and I want Meta to push money toward whatever is working best.
Scaling Bid Strategy: Bid Cap
The learning is done. I already know this creative converts and at what cost. Bid cap sets a hard ceiling per auction: you never bid above $X, period. Some delivery gets sacrificed because you won't win every auction at that ceiling, but you never overpay. At scale spend levels, a few uncapped auctions can blow your daily CPA. Bid cap prevents that.
The progression from testing to scaling is soft guardrails to hard ceilings. As creative moves from unproven to proven, cost controls tighten.
Scaling Ad Set Organization
These ad sets are evergreen. One per persona. They're permanent. Winners from testing move in. When they fatigue, they move out. But the ad set stays and keeps accumulating delivery history. The longer it runs, the smarter Lattice gets about who converts inside that persona.
This is the opposite of testing. In testing, ad sets are disposable. In scaling, ad sets are the asset.
Budget Scaling
I increase budget 20-30% at a time, sometimes more, no more than once a week, and only when CPA has been below target for five straight days. If CPA crosses 1.3x target after a budget increase, I pause scaling until it stabilizes. Patience is required. The algorithm needs time to recalibrate delivery at higher spend levels.
Fatigue Detection
Fatigue is when performance and distribution decline together. These signals moving in the same direction is the indicator. I don't tie fatigue to frequency. Frequency is a lagging metric that tells you what already happened. The performance and distribution signals tell you what's happening now.
| Signal | Threshold |
|---|---|
| CPA creep | Above target for 5 days |
| CTR decline | 20%+ over 14 days |
| CPM increase | 30%+ over 7 days |
| Delivery drop | Spend declining without budget change |
Expect 1-3 week refresh cycles under Andromeda. Creative fatigue has accelerated because the system finds optimal audiences faster and exhausts them faster.
When an ad fatigues, it moves to the catch-all. I don't kill it. It proved it could convert. It just can't sustain delivery at the scaling bid cap.
The Catch-All: The Bottom
Ads that showed promise in testing but didn't hit enough volume to graduate, and scaling winners that ran out of gas, both land here. One campaign across all products and markets. Advantage+ CBO with a bid cap set at roughly 0.7x my target CPA.
This isn't a dumping ground. It's a value extraction layer. If creative can still win auctions at that lower floor, I'm getting cheap conversions from proven creative. If it can't, delivery dies naturally. I pull anything that hasn't delivered in 14 days.
The catch-all exists because good creative doesn't suddenly become bad creative. It becomes fatigued creative. At a lower price point, it can often still convert profitably.
The Infrastructure
Exclusions
Every ad set across the entire account gets manual exclusions: 180-day purchasers, CRM buyers, existing customers. This prevents wasting top-of-funnel budget on people who already converted.
Naming Conventions
Every level of the account follows a strict naming convention:
- Campaign:
[Product]_[Geo]_[Phase]_[Date] - Ad Set (Testing):
[Persona]_[LP]_[Batch]_[Date] - Ad Set (Scaling):
[Persona]_[LP]_Evergreen - Ad Set (Catch-All):
[Product]_[Geo]_CatchAll - Ad:
[Persona]_[Format]_[Angle]_[Hook]_[Creator]_[Version]
This lets me segment performance by any attribute during analysis without opening a single ad set. When you're running 20+ campaigns, you need to filter by persona, format, angle, and creative concept at a glance. Naming conventions are operational infrastructure, not a nice-to-have.
Server-Side Tracking and CAPI
The whole system runs on server-side tracking through the Conversions API. Full event hierarchy: view content, add to cart, initiate checkout, purchase. The more funnel events Meta sees, the faster every system in the stack learns who converts.
Andromeda uses conversion signal quality as a factor in retrieval. Pixel-only tracking now penalizes your ad quality score. CAPI with proper deduplication directly improves how often your ads make it through the retrieval gate. This isn't optional.
The Click-Through Attribution Change (March 2026)
In March 2026, Meta changed the definition of click-through attribution for website and in-store conversions. Previously, any click on your ad counted toward click-through attribution: likes, shares, saves, comments, image expansions, video plays. If someone liked your ad on Tuesday and bought on Friday, Meta reported that as a click-through conversion.
Now, only link clicks count. Everything else moved to a new category called engage-through attribution with a 1-day window. Meta also shortened the video engaged-view threshold from 10 seconds to 5 seconds, reflecting the fact that 46% of Reels purchase conversions happen within the first two seconds of attention.
This matters for two reasons. First, your reported click-through conversions will drop. This is a reclassification, not a performance decline. Don't panic and change your campaigns in response. Give yourself two to three weeks to establish a new baseline before making any decisions.
Second, if you're comparing Meta Ads Manager numbers to Google Analytics, the gap just got smaller. GA always counted only link clicks. Meta was counting everything. Now they're closer to aligned. This is a good thing for cross-platform reporting, even if the short-term adjustment is uncomfortable.
I use incremental attribution as the primary model across all ad sets, which is a separate setting from click-through vs. engage-through. But if you're reading Ads Manager at the ad set or ad level for diagnostic purposes, you need to understand what the numbers mean now. Add engage-through as a visible column in your reporting so you're seeing the full picture.
Value Rules
I sometimes use value rules to bid higher for high-LTV customer segments without turning off automation. Value rules let you tell Meta "bid 40% more for women aged 25-44 in California" while keeping the rest of the campaign on autopilot. Use them only if you have concrete data showing one segment generates better long-term value than another. Without that data, you're just paying more for assumptions.
Creative Velocity: The Fuel
I feed the testing side two to three fresh creative batches per week. That's 6 to 15 new assets per week, each generating its own Entity ID. Without that cadence, the scaling side starves. Winners fatigue. The catch-all dries up. Everything decays.
| Metric | Target |
|---|---|
| New batches | 2-3 per week |
| Assets per batch | 3-5 |
| New Entity IDs | 6-15 per week |
| Persona rotation | Every ~1.5 weeks |
The entire system is a machine with an input and an output. The input is fresh creative. The output is profitable scale. The cadence is what connects them.
The Progression
Here's the logic that ties everything together:
Soft guardrails when learning. Hard ceilings when spending. As creative moves from unproven to proven to fatigued, cost controls tighten. tCPA/tROAS in testing gives room to explore. Bid cap in scaling protects margins. Lower bid cap in catch-all extracts residual value.
Testing ad sets are disposable. Scaling ad sets are the asset.
The creative finds the people. The structure protects the margin. The cadence keeps it alive.
This architecture was built inside real accounts, tested with real budgets, and revised until the math worked across brands spending six figures a month on Meta. The algorithm changed. The structure had to follow. This is what following looks like.
Structure is only one of three legs the 2026 algorithm depends on. The Meta ads performance system covers how creative diversity, signal density, and simplified structure reinforce each other — and what breaks when any one leg is missing.
Want help restructuring your Meta campaigns around these changes? Get a free growth audit or reach out directly.

Founder, GrowthMarketer
Co-founded TrueCoach, scaling it to 20,000 customers and an 8-figure exit. Now runs GrowthMarketer, helping scaling SaaS and DTC brands build AI-native growth systems and profitable paid acquisition engines.
I write about what's actually working in paid growth
Campaign teardowns, attribution fixes, and the systems behind 50+ brand partnerships — sent when I publish.
Unsubscribe anytime. Privacy policy


